Case Study
ebia-intelligence
A production LLM pipeline that turns thousands of public legal PDFs into a structured, searchable intelligence corpus — with verbatim-verified extraction and a self-maintaining vector index.
EB-1A appeals data pipeline · Live · 2026
By the numbers
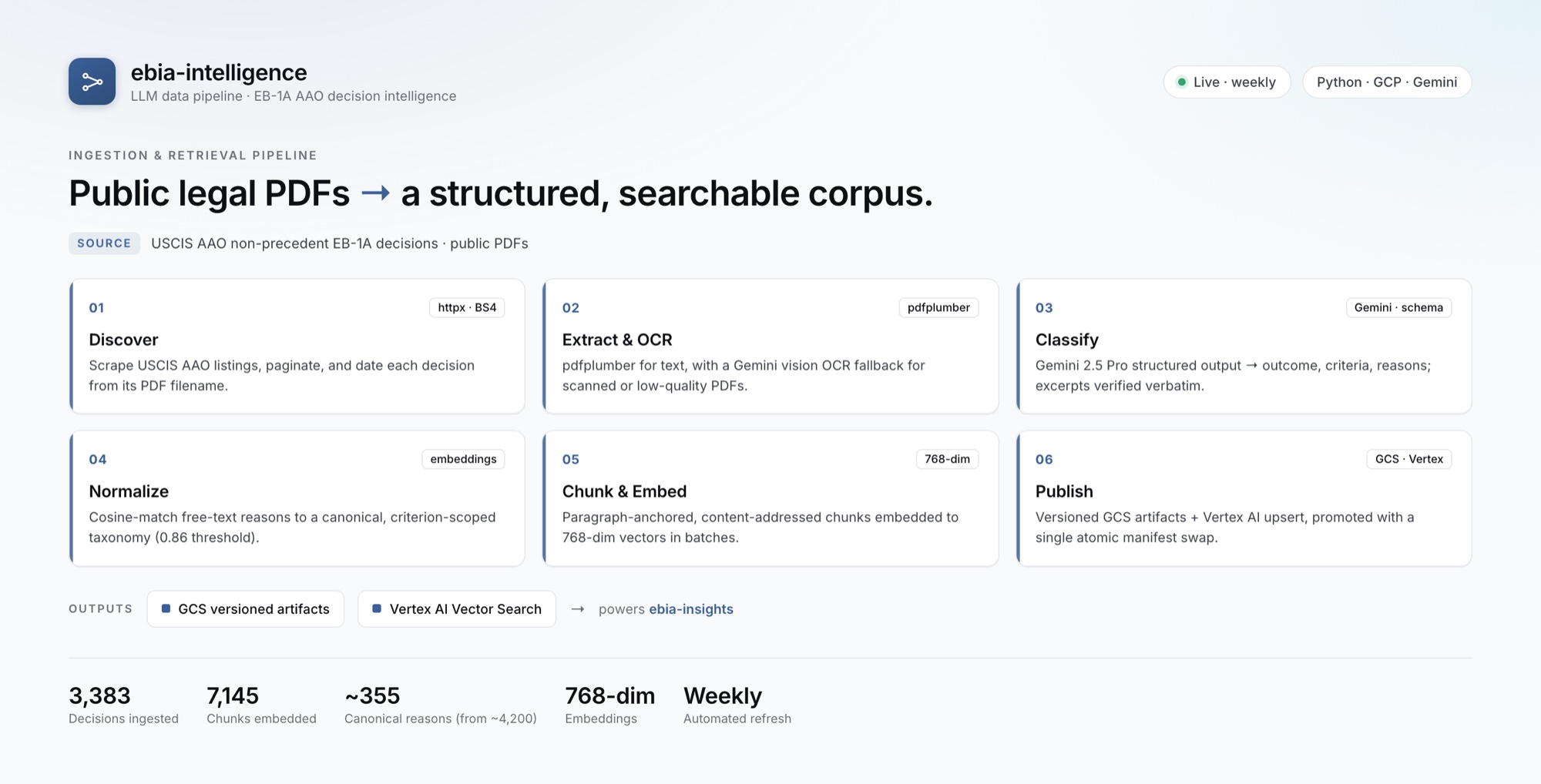
The shape of the system
Overview
What it is, and the problem it solves
The upstream data engine behind ebia-insights. A weekly serverless job discovers USCIS appeal decisions, extracts and classifies them with Gemini, canonicalizes their reasoning with embeddings, and publishes versioned artifacts plus a live Vertex AI vector index.
EB-1A denial patterns are buried across thousands of unstructured government PDFs — scanned, redacted, inconsistently formatted, and growing every week. The pipeline discovers, parses, and structures them into a clean, versioned corpus that downstream analytics and semantic search can trust, refreshed automatically with no human in the loop.
Engineering
Technical highlights
The decisions and techniques that make the system fast, current, and trustworthy.
LLM extraction with anti-hallucination guarantees
Gemini 2.5 Pro structured (schema-constrained) output classifies each decision into outcome, criteria, and denial reasons. Every quoted excerpt and extracted entity must be a literal substring of the source — anything the model invents is dropped before it can reach the corpus.
Embedding-based reason canonicalization
Free-text denial reasons collapse into a stable taxonomy via cosine similarity (a tuned 0.86 threshold) over Gemini embeddings, with a procedural "firewall" that never merges across regulatory subsections. ~4,200 raw labels reduce to ~355 canonical reasons.
A self-maintaining vector index
Builds and continuously updates a Vertex AI Vector Search index: content-addressed chunk IDs make reruns idempotent, stale datapoints are pruned when cases are reprocessed, and batched upserts respect quota and cost limits.
Idempotent, versioned data delivery
Six independent stages publish artifacts under a version, then promote them with a single atomic manifest swap — so readers never see partial data. Firestore-backed delta detection processes only what changed each week.
Architecture
How a request flows
Stack
Tech stack
Language
AI / Retrieval
Ingestion
Cloud / Infra
Quality
Why this matters for your team
What this project demonstrates
Production LLM pipelines, not prototypes
I run a live system that extracts structured data from messy legal PDFs every week — with verification that keeps model hallucinations out of a high-stakes corpus.
Retrieval infrastructure, end to end
From chunking strategy to embeddings to a self-pruning Vertex AI vector index, I build the data layer that makes RAG and semantic search actually trustworthy.
Data engineering that survives reruns
Idempotent, versioned, atomically-promoted artifacts and delta detection — the unglamorous discipline that keeps automated pipelines correct and cheap in production.
Next step
Building something similar?
Bring the problem, the constraints, and the timeline. I’ll help you design and ship it.